Распознавание образов. Начала теории. Теория распознавания образов
- Tutorial
Давно хотел написать общую статью, содержащую в себе самые основы Image Recognition, некий гайд по базовым методам, рассказывающий, когда их применять, какие задачи они решают, что возможно сделать вечером на коленке, а о чём лучше и не думать, не имея команды человек в 20.
Какие-то статьи по Optical Recognition я пишу давненько, так что пару раз в месяц мне пишут различные люди с вопросами по этой тематике. Иногда создаётся ощущение, что живёшь с ними в разных мирах. С одной стороны понимаешь, что человек скорее всего профессионал в смежной теме, но в методах оптического распознавания знает очень мало. И самое обидное, что он пытается применить метод из близрасположенной области знаний, который логичен, но в Image Recognition полностью не работает, но не понимает этого и сильно обижается, если ему начать рассказывать что-нибудь с самых основ. А учитывая, что рассказывать с основ - много времени, которого часто нет, становится всё ещё печальнее.
Эта статья задумана для того, чтобы человек, который никогда не занимался методами распознавания изображений, смог в течении 10-15 минут создать у себя в голове некую базовую картину мира, соответствующую тематике, и понять в какую сторону ему копать. Многие методы, которые тут описаны, применимы к радиолокации и аудио-обработке.
Начну с пары принципов, которые мы всегда начинаем рассказывать потенциальному заказчику, или человеку, который хочет начать заниматься Optical Recognition:
- При решении задачи всегда идти от простейшего. Гораздо проще повесить на персону метку оранжевого цвета, чем следить за человеком, выделяя его каскадами. Гораздо проще взять камеру с большим разрешением, чем разрабатывать сверхразрешающий алгоритм.
- Строгая постановка задачи в методах оптического распознавания на порядки важнее, чем в задачах системного программирования: одно лишнее слово в ТЗ может добавить 50% работы.
- В задачах распознавания нет универсальных решений. Нельзя сделать алгоритм, который будет просто «распознавать любую надпись». Табличка на улице и лист текста - это принципиально разные объекты. Наверное, можно сделать общий алгоритм( хороший пример от гугла), но это будет требовать огромного труда большой команды и состоять из десятков различных подпрограмм.
- OpenCV - это библия, в которой есть множество методов, и с помощью которой можно решить 50% от объёма почти любой задачи, но OpenCV - это лишь малая часть того, что в реальности можно сделать. В одном исследовании в выводах было написано: «Задача не решается методами OpenCV, следовательно, она неразрешима». Старайтесь избегать такого, не лениться и трезво оценивать текущую задачу каждый раз с нуля, не используя OpenCV-шаблоны.
Список приведённых тут методов не полон. Предлагаю в комментариях добавлять критические методы, которые я не написал и приписывать каждому по 2-3 сопроводительных слова.
Часть 1. Фильтрация
В эту группу я поместил методы, которые позволяют выделить на изображениях интересующие области, без их анализа. Большая часть этих методов применяет какое-то единое преобразование ко всем точкам изображения. На уровне фильтрации анализ изображения не производится, но точки, которые проходят фильтрацию, можно рассматривать как области с особыми характеристиками.Бинаризация по порогу, выбор области гистограммы
Самое просто преобразование - это бинаризация изображения по порогу. Для RGB изображения и изображения в градациях серого порогом является значение цвета. Встречаются идеальные задачи, в которых такого преобразования достаточно. Предположим, нужно автоматически выделить предметы на белом листе бумаги:

Выбор порога, по которому происходит бинаризация, во многом определяет процесс самой бинаризации. В данном случае, изображение было бинаризовано по среднему цвету. Обычно бинаризация осуществляется с помощью алгоритма, который адаптивно выбирает порог. Таким алгоритмом может быть выбор матожидания или моды . А можно выбрать наибольший пик гистограммы.

Бинаризация может дать очень интересные результаты при работе с гистограммами, в том числе в ситуации, если мы рассматриваем изображение не в RGB, а в HSV . Например, сегментировать интересующие цвета. На этом принципе можно построить как детектор метки так и детектор кожи человека.


Классическая фильтрация: Фурье, ФНЧ, ФВЧ
Классические методы фильтрации из радиолокации и обработки сигналов можно с успехом применять во множестве задач Pattern Recognition. Традиционным методом в радиолокации, который почти не используется в изображениях в чистом виде, является преобразование Фурье (конкретнее - БПФ). Одно из немногих исключение, при которых используется одномерное преобразование Фурье, - компрессия изображений . Для анализа изображений одномерного преобразования обычно не хватает, нужно использовать куда более ресурсоёмкое двумерное преобразование .
Мало кто его в действительности рассчитывает, обычно, куда быстрее и проще использовать свёртку интересующей области с уже готовым фильтром, заточенным на высокие (ФВЧ) или низкие(ФНЧ) частоты. Такой метод, конечно, не позволяет сделать анализ спектра, но в конкретной задаче видеообработки обычно нужен не анализ, а результат.


Самые простые примеры фильтров, реализующих подчёркивание низких частот (фильтр Гаусса) и высоких частот (Фильтр Габора).
Для каждой точки изображения выбирается окно и перемножается с фильтром того же размера. Результатом такой свёртки является новое значение точки. При реализации ФНЧ и ФВЧ получаются изображения такого типа:


Вейвлеты
Но что если использовать для свёртки с сигналом некую произвольную характеристическую функцию? Тогда это будет называться "Вейвлет-преобразование ". Это определение вейвлетов не является корректным, но традиционно сложилось, что во многих командах вейвлет-анализом называется поиск произвольного паттерна на изображении при помощи свёртки с моделью этого паттерна. Существует набор классических функций, используемых в вейвлет-анализе. К ним относятся вейвлет Хаара , вейвлет Морле , вейвлет мексиканская шляпа , и.т.д. Примитивы Хаара, про которые было несколько моих прошлых статей ( , ), относятся к таким функциям для двумерного пространства.



Выше приведено 4 примера классических вейвлетов. 3х-мерный вейвлет Хаара, 2х-мерные вейвлет Мейера, вейвлет Мексиканская Шляпа, вейвлет Добеши. Хорошим примером использования расширеной трактовки вейвлетов является задачка поиска блика в глазу, для которой вейвлетом является сам блик:

Классические вейвлеты обычно используются для , или для их классификации (будет описано ниже).
Корреляция
После такой вольной трактовки вейвлетов с моей стороны стоит упомянуть собственно корреляцию, лежащую в их основе. При фильтрации изображений это незаменимый инструмент. Классическое применение - корреляция видеопотока для нахождения сдвигов или оптических потоков. Простейший детектор сдвига - тоже в каком-то смысле разностный коррелятор. Там где изображения не коррелируют - было движение.


Фильтрации функций
Интересным классом фильтров является фильтрация функций. Это чисто математические фильтры, которые позволяют обнаружить простую математическую функцию на изображении (прямую, параболу, круг). Строится аккумулирующее изображение, в котором для каждой точки исходного изображения отрисовывается множество функций, её порождающих. Наиболее классическим преобразованием является преобразование Хафа для прямых. В этом преобразовании для каждой точки (x;y) отрисовывается множество точек (a;b) прямой y=ax+b, для которых верно равенство. Получаются красивые картинки:
(первый плюсег тому, кто первый найдёт подвох в картинке и таком определении и объяснит его, второй плюсег тому, кто первый скажет что тут изображено)
Преобразование Хафа позволяет находить любые параметризуемые функции. Например окружности . Есть модифицированное преобразование, которое позволяет искать любые . Это преобразование ужасно любят математики. Но вот при обработке изображений, оно, к сожалению, работает далеко не всегда. Очень медленная скорость работы, очень высокая чувствительность к качеству бинаризации. Даже в идеальных ситуациях я предпочитал обходиться другими методами.
Аналогом преобразования Хафа для прямых является преобразование Радона . Оно вычисляется через БПФ, что даёт выигрыш производительности в ситуации, когда точек очень много. К тому же его возможно применять к не бинаризованному изображению.
Фильтрации контуров
Отдельный класс фильтров - фильтрация границ и контуров . Контуры очень полезны, когда мы хотим перейти от работы с изображением к работе с объектами на этом изображении. Когда объект достаточно сложный, но хорошо выделяемый, то зачастую единственным способом работы с ним является выделение его контуров. Существует целый ряд алгоритмов, решающих задачу фильтрации контуров:Чаще всего используется именно Кэнни, который хорошо работает и реализация которого есть в OpenCV (Собель там тоже есть, но он хуже ищёт контуры).


Прочие фильтры
Сверху приведены фильтры, модификации которых помогают решить 80-90% задач. Но кроме них есть более редкие фильтры, используемые в локальных задачах. Таких фильтров десятки, я не буду приводить их все. Интересными являются итерационные фильтры (например ), а так же риджлет и курвлет преобразования, являющиеся сплавом классической вейвлет фильтрации и анализом в поле радон-преобразования. Бимлет-преобразование красиво работает на границе вейвлет преобразования и логического анализа, позволяя выделить контуры:
Но эти преобразования весьма специфичны и заточены под редкие задачи.
Часть 2. Логическая обработка результатов фильтрации
Фильтрация даёт набор пригодных для обработки данных. Но зачастую нельзя просто взять и использовать эти данные без их обработки. В этом разделе будет несколько классических методов, позволяющих перейти от изображения к свойствам объектов, или к самим объектам.Морфология
Переходом от фильтрации к логике, на мой взгляд, являются методы математической морфологии ( , ). По сути, это простейшие операции наращивания и эрозии бинарных изображений. Эти методы позволяют убрать шумы из бинарного изображения, увеличив или уменьшив имеющиеся элементы. На базе математической морфологии существуют алгоритмы оконтуривания, но обычно пользуются какими-то гибридными алгоритмами или алгоритмами в связке.
Контурный анализ
В разделе по фильтрации уже упоминались алгоритмы получения границ. Полученные границы достаточно просто преобразуются в контуры. Для алгоритма Кэнни это происходит автоматически, для остальных алгоритмов требуется дополнительная бинаризация. Получить контур для бинарного алгоритма можно например алгоритмом жука .Контур является уникальной характеристикой объекта. Часто это позволяет идентифицировать объект по контуру. Существует мощный математический аппарат, позволяющий это сделать. Аппарат называется контурным анализом ( , ).

Если честно, то у меня ни разу ни получилось применить контурный анализ в реальных задачах. Уж слишком идеальные условия требуются. То граница не найдётся, то шумов слишком много. Но, если нужно что-то распознавать в идеальных условиях - то контурный анализ замечательный вариант. Очень быстро работает, красивая математика и понятная логика.
Особые точки
Особые точки это уникальные характеристики объекта, которые позволяют сопоставлять объект сам с собой или с похожими классами объектов. Существует несколько десятков способов позволяющих выделить такие точки. Некоторые способы выделяют особые точки в соседних кадрах, некоторые через большой промежуток времени и при смене освещения, некоторые позволяют найти особые точки, которые остаются таковыми даже при поворотах объекта. Начнём с методов, позволяющих найти особые точки, которые не такие стабильные, зато быстро рассчитываются, а потом пойдём по возрастанию сложности:Первый класс. Особые точки, являющиеся стабильными на протяжении секунд. Такие точки служат для того, чтобы вести объект между соседними кадрами видео, или для сведения изображения с соседних камер. К таким точкам можно отнести локальные максимумы изображения, углы на изображении (лучший из детекторов, пожалуй, детектор Хариса), точки в которых достигается максимумы дисперсии, определённые градиенты и.т.д.
Второй класс. Особые точки, являющиеся стабильными при смене освещения и небольших движениях объекта. Такие точки служат в первую очередь для обучения и последующей классификации типов объектов. Например, классификатор пешехода или классификатор лица - это продукт системы, построенной именно на таких точках. Некоторые из ранее упомянутых вейвлетов могут являются базой для таких точек. Например, примитивы Хаара, поиск бликов, поиск прочих специфических функций. К таким точкам относятся точки, найденные методом гистограмм направленных градиентов (HOG).
Третий класс. Стабильные точки. Мне известно лишь про два метода, которые дают полную стабильность и про их модификации. Это и . Они позволяют находить особые точки даже при повороте изображения. Расчёт таких точек осуществляется дольше по сравнению с остальными методами, но достаточно ограниченное время. К сожалению эти методы запатентованы. Хотя, в России патентовать алгоритмы низя, так что для внутреннего рынка пользуйтесь.
Часть 3. Обучение
ретья часть рассказа будет посвящена методам, которые не работают непосредственно с изображением, но которые позволяют принимать решения. В основном это различные методы машинного обучения и принятия решений. Недавно Яндыкс выложил на Хабр по этой тематике, там очень хорошая подборка. Вот оно есть в текстовой версии. Для серьёзного занятия тематикой настоятельно рекомендую посмотреть именно их. Тут я попробую обозначить несколько основных методов используемых именно в распознавании образов.В 80% ситуаций суть обучения в задаче распознавания в следующем:
Имеется тестовая выборка, на которой есть несколько классов объектов. Пусть это будет наличие/отсутствие человека на фотографии. Для каждого изображения есть набор признаков, которые были выделены каким-нибудь признаком, будь то Хаар, HOG, SURF или какой-нибудь вейвлет. Алгоритм обучения должен построить такую модель, по которой он сумеет проанализировать новое изображение и принять решение, какой из объектов имеется на изображении.
Как это делается? Каждое из тестовых изображений - это точка в пространстве признаков. Её координаты это вес каждого из признаков на изображении. Пусть нашими признаками будут: «Наличие глаз», «Наличие носа», «Наличие двух рук», «Наличие ушей», и.т.д… Все эти признаки мы выделим существующими у нас детекторами, которые обучены на части тела, похожие на людские. Для человека в таком пространстве будет корректной точка . Для обезьяны точка для лошади . Классификатор обучается по выборке примеров. Но не на всех фотографиях выделились руки, на других нет глаз, а на третьей у обезьяны из-за ошибки классификатора появился человеческий нос. Обучаемый классификатор человека автоматически разбивает пространство признаков таким образом, чтобы сказать: если первый признак лежит в диапазоне 0.5




Существует очень много классификаторов. Каждый из них лучше работает в какой-то своей задачке. Задача подбора классификатора к конкретной задаче это во многом искусство. Вот немножко красивых картинок на тему.
Простой случай, одномерное разделение
Разберём на примере самый простой случай классификации, когда пространство признака одномерное, а нам нужно разделить 2 класса. Ситуация встречается чаще, чем может представиться: например, когда нужно отличить два сигнала, или сравнить паттерн с образцом. Пусть у нас есть обучающая выборка. При этом получается изображение, где по оси X будет мера похожести, а по оси Y -количество событий с такой мерой. Когда искомый объект похож на себя - получается левая гауссиана. Когда не похож - правая. Значение X=0.4 разделяет выборки так, что ошибочное решение минимизирует вероятность принятия любого неправильного решения. Именно поиском такого разделителя и является задача классификации.
Маленькая ремарка. Далеко не всегда оптимальным будет тот критерий, который минимизирует ошибку. Следующий график - это график реальной системы распознавания по радужной оболочке. Для такой системы критерий выбирается такой, чтобы минимизировать вероятность ложного пропуска постороннего человека на объект. Такая вероятность называется «ошибка первого рода», «вероятность ложной тревоги», «ложное срабатывание». В англоязычной литературе «False Access Rate ».
) АдаБуста - один из самых распространённых классификаторов. Например каскад Хаара построен именно на нём. Обычно используют когда нужна бинарная классификация, но ничего не мешает обучить на большее количество классов.
SVM ( , , , ) Один из самых мощных классификаторов, имеющий множество реализаций. В принципе, на задачах обучения, с которыми я сталкивался, он работал аналогично адабусте. Считается достаточно быстрым, но его обучение сложнее, чем у Адабусты и требуется выбор правильного ядра.
Ещё есть нейронные сети и регрессия. Но чтобы кратко их классифицировать и показать, чем они отличаются, нужна статья куда больше, чем эта.
________________________________________________
Надеюсь, у меня получилось сделать беглый обзор используемых методов без погружения в математику и описание. Может, кому-то это поможет. Хотя, конечно, статья неполна и нет ни слова ни о работе со стереоизображениями, ни о МНК с фильтром Калмана, ни об адаптивном байесовом подходе.
Если статья понравится, то попробую сделать вторую часть с подборкой примеров того, как решаются существующие задачки ImageRecognition.
И напоследок
Что почитать?1) Когда-то мне очень понравилась книга «Цифровая обработка изображений» Б. Яне, которая написана просто и понятно, но в то же время приведена почти вся математика. Хороша для того, чтобы ознакомиться с существующими методами.
2) Классикой жанра является Р Гонсалес, Р. Вудс " Цифровая обработка изображений ". Почему-то она мне далась сложнее, чем первая. Сильно меньше математики, зато больше методов и картинок.
3) «Обработка и анализ изображений в задачах машинного зрения» - написана на базе курса, читаемого на одной из кафедр ФизТеха. Очень много методов и их подробного описания. Но на мой взгляд в книге есть два больших минуса: книга сильно ориентирована на пакет софта, который к ней прилагается, в книге слишком часто описание простого метода превращается в математические дебри, из которых сложно вынести структурную схему метода. Зато авторы сделали удобный сайт, где представлено почти всё содержание - wiki.technicalvision.ru Добавить метки
- Tutorial
Давно хотел написать общую статью, содержащую в себе самые основы Image Recognition, некий гайд по базовым методам, рассказывающий, когда их применять, какие задачи они решают, что возможно сделать вечером на коленке, а о чём лучше и не думать, не имея команды человек в 20.
Какие-то статьи по Optical Recognition я пишу давненько, так что пару раз в месяц мне пишут различные люди с вопросами по этой тематике. Иногда создаётся ощущение, что живёшь с ними в разных мирах. С одной стороны понимаешь, что человек скорее всего профессионал в смежной теме, но в методах оптического распознавания знает очень мало. И самое обидное, что он пытается применить метод из близрасположенной области знаний, который логичен, но в Image Recognition полностью не работает, но не понимает этого и сильно обижается, если ему начать рассказывать что-нибудь с самых основ. А учитывая, что рассказывать с основ - много времени, которого часто нет, становится всё ещё печальнее.
Эта статья задумана для того, чтобы человек, который никогда не занимался методами распознавания изображений, смог в течении 10-15 минут создать у себя в голове некую базовую картину мира, соответствующую тематике, и понять в какую сторону ему копать. Многие методы, которые тут описаны, применимы к радиолокации и аудио-обработке.
Начну с пары принципов, которые мы всегда начинаем рассказывать потенциальному заказчику, или человеку, который хочет начать заниматься Optical Recognition:
- При решении задачи всегда идти от простейшего. Гораздо проще повесить на персону метку оранжевого цвета, чем следить за человеком, выделяя его каскадами. Гораздо проще взять камеру с большим разрешением, чем разрабатывать сверхразрешающий алгоритм.
- Строгая постановка задачи в методах оптического распознавания на порядки важнее, чем в задачах системного программирования: одно лишнее слово в ТЗ может добавить 50% работы.
- В задачах распознавания нет универсальных решений. Нельзя сделать алгоритм, который будет просто «распознавать любую надпись». Табличка на улице и лист текста - это принципиально разные объекты. Наверное, можно сделать общий алгоритм(вот хороший пример от гугла), но это будет требовать огромного труда большой команды и состоять из десятков различных подпрограмм.
- OpenCV - это библия, в которой есть множество методов, и с помощью которой можно решить 50% от объёма почти любой задачи, но OpenCV - это лишь малая часть того, что в реальности можно сделать. В одном исследовании в выводах было написано: «Задача не решается методами OpenCV, следовательно, она неразрешима». Старайтесь избегать такого, не лениться и трезво оценивать текущую задачу каждый раз с нуля, не используя OpenCV-шаблоны.
Список приведённых тут методов не полон. Предлагаю в комментариях добавлять критические методы, которые я не написал и приписывать каждому по 2-3 сопроводительных слова.
Часть 1. Фильтрация
В эту группу я поместил методы, которые позволяют выделить на изображениях интересующие области, без их анализа. Большая часть этих методов применяет какое-то единое преобразование ко всем точкам изображения. На уровне фильтрации анализ изображения не производится, но точки, которые проходят фильтрацию, можно рассматривать как области с особыми характеристиками.Бинаризация по порогу, выбор области гистограммы
Самое просто преобразование - это бинаризация изображения по порогу. Для RGB изображения и изображения в градациях серого порогом является значение цвета. Встречаются идеальные задачи, в которых такого преобразования достаточно. Предположим, нужно автоматически выделить предметы на белом листе бумаги:Выбор порога, по которому происходит бинаризация, во многом определяет процесс самой бинаризации. В данном случае, изображение было бинаризовано по среднему цвету. Обычно бинаризация осуществляется с помощью алгоритма, который адаптивно выбирает порог. Таким алгоритмом может быть выбор матожидания или моды . А можно выбрать наибольший пик гистограммы.
Бинаризация может дать очень интересные результаты при работе с гистограммами, в том числе в ситуации, если мы рассматриваем изображение не в RGB, а в HSV . Например, сегментировать интересующие цвета. На этом принципе можно построить как детектор метки так и детектор кожи человека.
Классическая фильтрация: Фурье, ФНЧ, ФВЧ
Классические методы фильтрации из радиолокации и обработки сигналов можно с успехом применять во множестве задач Pattern Recognition. Традиционным методом в радиолокации, который почти не используется в изображениях в чистом виде, является преобразование Фурье (конкретнее - БПФ). Одно из немногих исключение, при которых используется одномерное преобразование Фурье, - компрессия изображений . Для анализа изображений одномерного преобразования обычно не хватает, нужно использовать куда более ресурсоёмкое двумерное преобразование .Мало кто его в действительности рассчитывает, обычно, куда быстрее и проще использовать свёртку интересующей области с уже готовым фильтром, заточенным на высокие (ФВЧ) или низкие(ФНЧ) частоты. Такой метод, конечно, не позволяет сделать анализ спектра, но в конкретной задаче видеообработки обычно нужен не анализ, а результат.
Самые простые примеры фильтров, реализующих подчёркивание низких частот (фильтр Гаусса) и высоких частот (Фильтр Габора).
Для каждой точки изображения выбирается окно и перемножается с фильтром того же размера. Результатом такой свёртки является новое значение точки. При реализации ФНЧ и ФВЧ получаются изображения такого типа:
Вейвлеты
Но что если использовать для свёртки с сигналом некую произвольную характеристическую функцию? Тогда это будет называться "Вейвлет-преобразование ". Это определение вейвлетов не является корректным, но традиционно сложилось, что во многих командах вейвлет-анализом называется поиск произвольного паттерна на изображении при помощи свёртки с моделью этого паттерна. Существует набор классических функций, используемых в вейвлет-анализе. К ним относятся вейвлет Хаара , вейвлет Морле , вейвлет мексиканская шляпа , и.т.д. Примитивы Хаара, про которые было несколько моих прошлых статей ( , ), относятся к таким функциям для двумерного пространства.Выше приведено 4 примера классических вейвлетов. 3х-мерный вейвлет Хаара, 2х-мерные вейвлет Мейера, вейвлет Мексиканская Шляпа, вейвлет Добеши. Хорошим примером использования расширеной трактовки вейвлетов является задачка поиска блика в глазу, для которой вейвлетом является сам блик:
Классические вейвлеты обычно используются для сжатия изображений , или для их классификации (будет описано ниже).
Корреляция
После такой вольной трактовки вейвлетов с моей стороны стоит упомянуть собственно корреляцию, лежащую в их основе. При фильтрации изображений это незаменимый инструмент. Классическое применение - корреляция видеопотока для нахождения сдвигов или оптических потоков. Простейший детектор сдвига - тоже в каком-то смысле разностный коррелятор. Там где изображения не коррелируют - было движение.Фильтрации функций
Интересным классом фильтров является фильтрация функций. Это чисто математические фильтры, которые позволяют обнаружить простую математическую функцию на изображении (прямую, параболу, круг). Строится аккумулирующее изображение, в котором для каждой точки исходного изображения отрисовывается множество функций, её порождающих. Наиболее классическим преобразованием является преобразование Хафа для прямых. В этом преобразовании для каждой точки (x;y) отрисовывается множество точек (a;b) прямой y=ax+b, для которых верно равенство. Получаются красивые картинки:(первый плюсег тому, кто первый найдёт подвох в картинке и таком определении и объяснит его, второй плюсег тому, кто первый скажет что тут изображено)
Преобразование Хафа позволяет находить любые параметризуемые функции. Например окружности . Есть модифицированное преобразование, которое позволяет искать любые фигуры . Это преобразование ужасно любят математики. Но вот при обработке изображений, оно, к сожалению, работает далеко не всегда. Очень медленная скорость работы, очень высокая чувствительность к качеству бинаризации. Даже в идеальных ситуациях я предпочитал обходиться другими методами.
Аналогом преобразования Хафа для прямых является преобразование Радона . Оно вычисляется через БПФ, что даёт выигрыш производительности в ситуации, когда точек очень много. К тому же его возможно применять к не бинаризованному изображению.
Фильтрации контуров
Отдельный класс фильтров - фильтрация границ и контуров . Контуры очень полезны, когда мы хотим перейти от работы с изображением к работе с объектами на этом изображении. Когда объект достаточно сложный, но хорошо выделяемый, то зачастую единственным способом работы с ним является выделение его контуров. Существует целый ряд алгоритмов, решающих задачу фильтрации контуров:Чаще всего используется именно Кэнни, который хорошо работает и реализация которого есть в OpenCV (Собель там тоже есть, но он хуже ищёт контуры).
Прочие фильтры
Сверху приведены фильтры, модификации которых помогают решить 80-90% задач. Но кроме них есть более редкие фильтры, используемые в локальных задачах. Таких фильтров десятки, я не буду приводить их все. Интересными являются итерационные фильтры (например активная модель внешнего вида), а так же риджлет и курвлет преобразования, являющиеся сплавом классической вейвлет фильтрации и анализом в поле радон-преобразования. Бимлет-преобразование красиво работает на границе вейвлет преобразования и логического анализа, позволяя выделить контуры:Но эти преобразования весьма специфичны и заточены под редкие задачи.
Часть 2. Логическая обработка результатов фильтрации
Фильтрация даёт набор пригодных для обработки данных. Но зачастую нельзя просто взять и использовать эти данные без их обработки. В этом разделе будет несколько классических методов, позволяющих перейти от изображения к свойствам объектов, или к самим объектам.Морфология
Переходом от фильтрации к логике, на мой взгляд, являются методы математической морфологии ( , , ). По сути, это простейшие операции наращивания и эрозии бинарных изображений. Эти методы позволяют убрать шумы из бинарного изображения, увеличив или уменьшив имеющиеся элементы. На базе математической морфологии существуют алгоритмы оконтуривания, но обычно пользуются какими-то гибридными алгоритмами или алгоритмами в связке.Контурный анализ
В разделе по фильтрации уже упоминались алгоритмы получения границ. Полученные границы достаточно просто преобразуются в контуры. Для алгоритма Кэнни это происходит автоматически, для остальных алгоритмов требуется дополнительная бинаризация. Получить контур для бинарного алгоритма можно например алгоритмом жука .Контур является уникальной характеристикой объекта. Часто это позволяет идентифицировать объект по контуру. Существует мощный математический аппарат, позволяющий это сделать. Аппарат называется контурным анализом ( , ).
Если честно, то у меня ни разу ни получилось применить контурный анализ в реальных задачах. Уж слишком идеальные условия требуются. То граница не найдётся, то шумов слишком много. Но, если нужно что-то распознавать в идеальных условиях - то контурный анализ замечательный вариант. Очень быстро работает, красивая математика и понятная логика.
Особые точки
Особые точки это уникальные характеристики объекта, которые позволяют сопоставлять объект сам с собой или с похожими классами объектов. Существует несколько десятков способов позволяющих выделить такие точки. Некоторые способы выделяют особые точки в соседних кадрах, некоторые через большой промежуток времени и при смене освещения, некоторые позволяют найти особые точки, которые остаются таковыми даже при поворотах объекта. Начнём с методов, позволяющих найти особые точки, которые не такие стабильные, зато быстро рассчитываются, а потом пойдём по возрастанию сложности:Первый класс. Особые точки, являющиеся стабильными на протяжении секунд. Такие точки служат для того, чтобы вести объект между соседними кадрами видео, или для сведения изображения с соседних камер. К таким точкам можно отнести локальные максимумы изображения, углы на изображении (лучший из детекторов, пожалуй, детектор Хариса), точки в которых достигается максимумы дисперсии, определённые градиенты и.т.д.
Второй класс. Особые точки, являющиеся стабильными при смене освещения и небольших движениях объекта. Такие точки служат в первую очередь для обучения и последующей классификации типов объектов. Например, классификатор пешехода или классификатор лица - это продукт системы, построенной именно на таких точках. Некоторые из ранее упомянутых вейвлетов могут являются базой для таких точек. Например, примитивы Хаара, поиск бликов, поиск прочих специфических функций. К таким точкам относятся точки, найденные методом гистограмм направленных градиентов (HOG).
Третий класс. Стабильные точки. Мне известно лишь про два метода, которые дают полную стабильность и про их модификации. Это SURF и SIFT . Они позволяют находить особые точки даже при повороте изображения. Расчёт таких точек осуществляется дольше по сравнению с остальными методами, но достаточно ограниченное время. К сожалению эти методы запатентованы. Хотя, в России патентовать алгоритмы низя, так что для внутреннего рынка пользуйтесь.
Часть 3. Обучение
ретья часть рассказа будет посвящена методам, которые не работают непосредственно с изображением, но которые позволяют принимать решения. В основном это различные методы машинного обучения и принятия решений. Недавно Яндыкс выложил на Хабр курс по этой тематике, там очень хорошая подборка. Вот оно есть в текстовой версии. Для серьёзного занятия тематикой настоятельно рекомендую посмотреть именно их. Тут я попробую обозначить несколько основных методов используемых именно в распознавании образов.В 80% ситуаций суть обучения в задаче распознавания в следующем:
Имеется тестовая выборка, на которой есть несколько классов объектов. Пусть это будет наличие/отсутствие человека на фотографии. Для каждого изображения есть набор признаков, которые были выделены каким-нибудь признаком, будь то Хаар, HOG, SURF или какой-нибудь вейвлет. Алгоритм обучения должен построить такую модель, по которой он сумеет проанализировать новое изображение и принять решение, какой из объектов имеется на изображении.
Как это делается? Каждое из тестовых изображений - это точка в пространстве признаков. Её координаты это вес каждого из признаков на изображении. Пусть нашими признаками будут: «Наличие глаз», «Наличие носа», «Наличие двух рук», «Наличие ушей», и.т.д… Все эти признаки мы выделим существующими у нас детекторами, которые обучены на части тела, похожие на людские. Для человека в таком пространстве будет корректной точка . Для обезьяны точка для лошади . Классификатор обучается по выборке примеров. Но не на всех фотографиях выделились руки, на других нет глаз, а на третьей у обезьяны из-за ошибки классификатора появился человеческий нос. Обучаемый классификатор человека автоматически разбивает пространство признаков таким образом, чтобы сказать: если первый признак лежит в диапазоне 0.5
Существует очень много классификаторов. Каждый из них лучше работает в какой-то своей задачке. Задача подбора классификатора к конкретной задаче это во многом искусство. Вот немножко красивых картинок на тему.
Простой случай, одномерное разделение
Разберём на примере самый простой случай классификации, когда пространство признака одномерное, а нам нужно разделить 2 класса. Ситуация встречается чаще, чем может представиться: например, когда нужно отличить два сигнала, или сравнить паттерн с образцом. Пусть у нас есть обучающая выборка. При этом получается изображение, где по оси X будет мера похожести, а по оси Y -количество событий с такой мерой. Когда искомый объект похож на себя - получается левая гауссиана. Когда не похож - правая. Значение X=0.4 разделяет выборки так, что ошибочное решение минимизирует вероятность принятия любого неправильного решения. Именно поиском такого разделителя и является задача классификации.Маленькая ремарка. Далеко не всегда оптимальным будет тот критерий, который минимизирует ошибку. Следующий график - это график реальной системы распознавания по радужной оболочке. Для такой системы критерий выбирается такой, чтобы минимизировать вероятность ложного пропуска постороннего человека на объект. Такая вероятность называется «ошибка первого рода», «вероятность ложной тревоги», «ложное срабатывание». В англоязычной литературе «False Access Rate ».
) АдаБуста - один из самых распространённых классификаторов. Например каскад Хаара построен именно на нём. Обычно используют когда нужна бинарная классификация, но ничего не мешает обучить на большее количество классов.
SVM ( , , , ) Один из самых мощных классификаторов, имеющий множество реализаций. В принципе, на задачах обучения, с которыми я сталкивался, он работал аналогично адабусте. Считается достаточно быстрым, но его обучение сложнее, чем у Адабусты и требуется выбор правильного ядра.
Ещё есть нейронные сети и регрессия. Но чтобы кратко их классифицировать и показать, чем они отличаются, нужна статья куда больше, чем эта.
________________________________________________
Надеюсь, у меня получилось сделать беглый обзор используемых методов без погружения в математику и описание. Может, кому-то это поможет. Хотя, конечно, статья неполна и нет ни слова ни о работе со стереоизображениями, ни о МНК с фильтром Калмана, ни об адаптивном байесовом подходе.
Если статья понравится, то попробую сделать вторую часть с подборкой примеров того, как решаются существующие задачки ImageRecognition.
И напоследок
Что почитать?1) Когда-то мне очень понравилась книга «Цифровая обработка изображений» Б. Яне, которая написана просто и понятно, но в то же время приведена почти вся математика. Хороша для того, чтобы ознакомиться с существующими методами.
2) Классикой жанра является Р Гонсалес, Р. Вудс " Цифровая обработка изображений ". Почему-то она мне далась сложнее, чем первая. Сильно меньше математики, зато больше методов и картинок.
3) «Обработка и анализ изображений в задачах машинного зрения» - написана на базе курса, читаемого на одной из кафедр ФизТеха. Очень много методов и их подробного описания. Но на мой взгляд в книге есть два больших минуса: книга сильно ориентирована на пакет софта, который к ней прилагается, в книге слишком часто описание простого метода превращается в математические дебри, из которых сложно вынести структурную схему метода. Зато авторы сделали удобный сайт, где представлено почти всё содержание - wiki.technicalvision.ru Добавить метки
В целом, можно выделить три метода распознавания образов: Метод перебора. В этом случае производится сравнение с базой данных, где для каждого вида объектов представлены всевозможные модификации отображения. Например, для оптического распознавания образов можно применить метод перебора вида объекта под различными углами, масштабами, смещениями, деформациями и т. д. Для букв нужно перебирать шрифт, свойства шрифта и т. д. В случае распознавания звуковых образов, соответственно, происходит сравнение с некоторыми известными шаблонами (например, слово, произнесенное несколькими людьми).
Второй подход - производится более глубокий анализ характеристик образа. В случае оптического распознавания это может быть определение различных геометрических характеристик. Звуковой образец в этом случае подвергается частотному, амплитудному анализу и т. д.
Следующий метод - использование искусственных нейронных сетей (ИНС). Этот метод требует либо большого количества примеров задачи распознавания при обучении, либо специальной структуры нейронной сети, учитывающей специфику данной задачи. Тем не менее, его отличает более высокая эффективность и производительность.
4. История распознавания образов
Рассмотрим кратко математический формализм распознавания образов. Объект в распознавании образов описывается совокупностью основных характеристик (признаков, свойств). Основные характеристики могут иметь различную природу: они могут браться из упорядоченного множества типа вещественной прямой, либо из дискретного множества (которое, впрочем, так же может быть наделено структурой). Такое понимание объекта согласуется как потребностью практических приложений распознавания образов, так и с нашим пониманием механизма восприятия объекта человеком. Действительно, мы полагаем, что при наблюдении (измерении) объекта человеком, сведения о нем поступают по конечному числу сенсоров (анализируемых каналов) в мозг, и каждому сенсору можно сопоставить соответствующую характеристику объекта. Помимо признаков, соответствующих нашим измерениям объекта, существует так же выделенный признак, либо группа признаков, которые мы называем классифицирующими признаками, и в выяснении их значений при заданном векторе Х и состоит задача, которую выполняют естественные и искусственные распознающие системы.
Понятно, что для того, чтобы установить значения этих признаков, необходимо иметь информацию о том, как связаны известные признаки с классифицирующими. Информация об этой связи задается в форме прецедентов, то есть множества описаний объектов с известными значениями классифицирующих признаков. И по этой прецедентной информации и требуется построить решающее правило, которое будет ставить произвольному описанию объекта значения его классифицирующих признаков.
Такое понимание задачи распознавания образов утвердилось в науке начиная с 50-х годов прошлого века. И тогда же было замечено что такая постановка вовсе не является новой. С подобной формулировкой сталкивались и уже существовали вполне не плохо зарекомендовавшие себя методы статистического анализа данных, которые активно использовались для многих практических задач, таких как например, техническая диагностика. Поэтому первые шаги распознавания образов прошли под знаком статистического подхода, который и диктовал основную проблематику.
Статистический подход основывается на идее, что исходное пространство объектов представляет собой вероятностное пространство, а признаки (характеристики) объектов являют собой случайные величины заданные на нем. Тогда задача исследователя данных состояла в том, чтобы из некоторых соображений выдвинуть статистическую гипотезу о распределении признаков, а точнее о зависимости классифицирующих признаков от остальных. Статистическая гипотеза, как правило, представляла собой параметрически заданное множество функций распределения признаков. Типичной и классической статистической гипотезой является гипотеза о нормальности этого распределения (разновидностей таких гипотез статистики придумали великое множество). После формулировки гипотезы оставалось проверить эту гипотезу на прецедентных данных. Это проверка состояла в выборе некоторого распределения из первоначально заданного множества распределений (параметра гипотезы о распределении) и оценки надежности(доверительного интервала) этого выбора. Собственно эта функция распределения и была ответом к задаче, только объект классифицировался уже не однозначно, но с некоторыми вероятностями принадлежности к классам. Статистиками были разработано так же и ассимптотическое обоснование таких методов. Такие обоснования делались по следующей схеме: устанавливался некоторый функционал качества выбора распределения (доверительный интервал) и показывалось, что при увеличении числа прецедентов, наш выбор с вероятностью стремящейся к 1 становился верным в смысле этого функционала (доверительный интервал стремился к 0). Забегая вперед скажем, что статистический взгляд на проблему распознавания оказался весьма плодотворным не только в смысле разработанных алгоритмов (в число которых входят методы кластерного, дискриминантного анализов, непараметрическая регрессия и т.д.), но и привел впоследствии Вапника к созданию глубокой статистической теории распознавания.
Тем не менее существует серьезная аргументация в пользу того, что задачи распознавания образов не сводятся к статистике. Любую такую задачу, в принципе, можно рассматривать со статистической точки зрения и результаты ее решения могут интерпретироваться статистически. Для этого необходимо лишь предположить, что пространство объектов задачи является вероятностным. Но с точки зрения инструментализма, критерием удачности статистической интерпретации некоторого метода распознавания может служить лишь наличие обоснавания этого метода на языке статистики как раздела математики. Под обоснаванием здесь понимается выработка основных требований к задаче которые обеспечивают успех в применении этого метода. Однако на данный момент для большей части методов распознавания, в том числе и для тех, которые напрямую возникли в рамках статистического подхода, подобных удовлетворительных обоснований не найдено. Кроме этого, наиболее часто применяемые на данный момент статистические алгоритмы, типа линейного дискриминанта Фишера, парзеновского окна, EM-алгоритма, метода ближайших соседей, не говоря уже о байесовских сетях доверия, имеют сильно выраженный эвристический характер и могут иметь интерпретации отличные от статистических. И наконец, ко всему вышесказанному следует добавить, что помимо асимптотического поведения методов распознавания, которое и является основным вопросом статистики, практика распознавания ставит вопросы вычислительной и структурной сложности методов, которые выводят далеко за рамки одной лишь теории вероятностей.
Итого, вопреки стремлениям статистиков рассматривать распознавание образов как раздел статистики, в практику и идеологию распознавания входили совершенно другие идеи. Одна из них была вызвана исследованиями в области распознавания зрительных образов и основана на следующей аналогии.
Как уже отмечалось, в повседневной жизни люди постоянно решают (зачастую бессознательно) проблемы распознавания различных ситуаций, слуховых и зрительных образов. Подобная способность для ЭВМ представляет собой в лучшем случае дело будущего. Отсюда некоторыми пионерами распознавания образов был сделан вывод, что решение этих проблем на ЭВМ должно в общих чертах моделировать процессы человеческого мышления. Наиболее известной попыткой подойти к проблеме с этой стороны было знаменитое исследование Ф. Розенблатта по перцептронам .
К середине 50-х годов казалось, что нейрофизиологами были поняты физические принципы работы мозга (в книге "Новый Разум Короля" знаменитый британский физик-теоретик Р. Пенроуз интересно ставит под сомнение нейросетевую модель мозга, обосновывая существенную роль в его функционировании квантово-механических эффектов; хотя, впрочем, эта модель подвергалась сомнению с самого начала. Отталкиваясь от этих открытий Ф.Розенблатт разработал модель обучения распознаванию зрительных образов, названную им персептроном. Персептрон Розенблатта представляет собой следующую функцию (рис. 1):
Рис 1. Схема Персептрона
На входе персептрон получает вектор объекта, который в работах Розенблатта представлял собой бинарный вектор, показывавший какой из пикселов экрана зачернен изображением а какой нет. Далее каждый из признаков подается на вход нейрона, действие которого представляет собой простое умножение на некоторый вес нейрона. Результаты подаются на последний нейрон, который их складывает и общую сумму сравнивает с некоторым порогом. В зависимости от результатов сравнения входной объект Х признается нужным образом либо нет. Тогда задача обучения распознаванию образов состояла в таком подборе весов нейронов и значения порога, чтобы персептрон давал на прецедентных зрительных образах правильные ответы. Розенблатт полагал, что получившаяся функция будет неплохо распознавать нужный зрительный образ даже если входного объекта и не было среди прецедентов. Из бионических соображений им так же был придуман и метод подбора весов и порога, на котором останавливаться мы не будем. Скажем лишь, что его подход оказался успешным в ряде задач распознавания и породил собой целое направление исследований алгоритмов обучения основанных на нейронных сетях, частным случаем которых и является персептрон.
Далее были придуманы различные обобщения персептрона, функция нейронов была усложнена: нейроны теперь могли не только умножать входные числа или складывать их и сравнивать результат с порогами, но применять по отношению к ним более сложные функции. На рисунке 2 изображено одно из подобных усложнений нейрона:

Рис. 2 Схема нейронной сети.
Кроме того топология нейронной сети могла быть значительно сложнее той, что рассматривал Розенблатт, например такой:
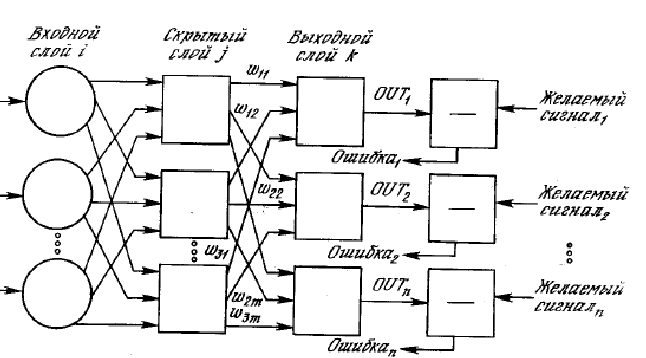
Рис. 3. Схема нейронной сети Розенблатта.
Усложнения приводили к увеличению числа настраиваемых параметров при обучении, но при этом увеличивали возможность настраиваться на очень сложные закономерности. Исследования в этой области сейчас идут по двум тесно связанным направлениям - изучаются и различные топологии сетей и различные методы настроек.
Нейронные сети на данный момент являются не только инструментом решения задач распознавания образов, но получили применение в исследованиях по ассоциативной памяти, сжатию изображений. Хотя это направление исследований и пересекается сильно с проблематикой распознавания образов, но представляет собой отдельный раздел кибернетики. Для распознавателя на данный момент, нейронные сети не более чем очень специфически определенное, параметрически заданное множество отображений, которое в этом смысле не имеет каких-либо существенных преимуществ над многими другим подобными моделями обучения которые далее будут кратко перечислены.
В связи с данной оценкой роли нейронных сетей для собственно распознавания (то есть не для бионики, для которой они имеют первостепенное значение уже сейчас) хотелось бы отметить следующее: нейронные сети, будучи чрезвычайно сложным объектом для математического анализа, при грамотном их использовании, позволяют находить весьма нетривиальные законы в данных. Их трудность для анализа, в общем случае, объясняется их сложной структурой и как следствие, практически неисчерпаемыми возможностями для обобщения самых различных закономерностей. Но эти достоинства, как это часто и бывает, являются источником потенциальных ошибок, возможности переобучения. Как будет рассказано далее, подобный двоякий взгляд на перспективы всякой модели обучения является одним из принципов машинного обучения.
Еще одним популярным направлением в распознавании являются логические правила и деревья решений. В сравнении с вышеупомянутыми методами распознавания эти методы наиболее активно используют идею выражения наших знаний о предметной области в виде, вероятно самых естественных (на сознательном уровне) структур - логических правил. Под элементарным логическим правилом подразумевается высказывание типа «если неклассифицируемые признаки находятся в соотношении X то классифицируемые находятся в соотношении Y». Примером такого правила в медицинской диагностике служит следующее: если возраст пациента выше 60 лет и ранее он перенёс инфаркт, то операцию не делать - риск отрицательного исхода велик.
Для поиска логических правил в данных необходимы 2 вещи: определить меру «информативности» правила и пространство правил. И задача поиска правил после этого превращается в задачу полного либо частичного перебора в пространстве правил с целью нахождения наиболее информативных из них. Определение информативности может быть введено самыми различными способами и мы не будем останавливаться на этом, считая что это тоже некоторый параметр модели. Пространство же поиска определяется стандартно.
После нахождения достаточно информативных правил наступает фаза «сборки» правил в конечный классификатор. Не обсуждая глубоко проблемы которые здесь возникают (а их возникает немалое количество) перечислим 2 основных способа «сборки». Первый тип - линейный список. Второй тип – взвешенное голосование, когда каждому правилу ставится в соответствие некоторый вес, и объект относится классификатором к тому классу за который проголосовало наибольшее количество правил.
В действительности, этап построения правил и этап «сборки» выполняются сообща и, при построении взвешенного голосования либо списка, поиск правил на частях прецедентных данных вызывается снова и снова, чтобы обеспечить лучшее согласование данных и модели.
Распознавание образов - научное направление, связанное с разработкой принципов и построением систем, предназначенных для определения принадлежности данного объекта к одному из заранее выделенных классов объектов.
Введение
С развитием вычислительной техники стало возможным решить ряд задач, возникающих в процессе жизнедеятельности, облегчить, ускорить, повысить качество результата. К примеру, работа различных систем жизнеобеспечения, взаимодействие человека с компьютером, появление роботизированных систем и др. Тем не менее, отметим, что обеспечить удовлетворительный результат в некоторых задачах (распознавание быстродвижущихся подобных объектов, рукописного текста) в настоящее время не удается. Таким образом, в этой статье предлагается обсудить методы и принципы, применяемые в вычислительной технике для выполнения поставленной задачи.
Задача поиска изображения по образцу является частью (подзадачей) более общей задачи распознавания образов. При несистематизированном и ненаправленном поиске «схожих» объектов из множества объектов, их можно перечислять бесконечно долго и не прийти к завершению с заданной вероятностью. В частных случаях объекты характеризуются такими идентификационными параметрами(признаками), как форма, цвет, положение, подвижность, по отличительным особенностям, их комбинации и т.п. В зависимости от этих факторов объекты подвергаются классификации. Часто стоит не глобальная задача классификации всех окружающих объектов, а необходимость выделить в поступающем видео-потоке объекты определенного рода. Далее рассмотрены наиболее распространенные классификационные признаке.
Классификация
Классификация по форме
Когда встает задача выделить объекты по форме, должны быть заданы классификационные примитивы. В большинстве методов поиска в качестве примитивов используются круглые, эллиптические, прямоугольные или прямолинейные объекты.
Поиск по шаблону
Универсальным способом поиска по форме признан метод вписывания шаблона. Шаблон, имеющий форму, объекты которой необходимо выделить, перемещается по изображению, рассчитывается характеристика положения, и там, где показатель этой характеристики превышает некоторый порог – может находиться объект искомой формы.

Рис. 1. Обход картинки шаблоном

Рис. 2. Определение вероятного местоположения
Техника расчета характеристики может быть различна. Чаще всего используется среднеквадратичная разность значений яркости изображений шаблона и анализируемого кадра.
Недостатком этого метода является его ресурсоемкость. Требуется неоднократное непоследовательное обращение к одним и тем же фрагментам памяти изображения. К тому же, изображение шаблона не является динамически масштабируемым – то есть, если объект в кадре несколько меньше или больше шаблонного – он, скорее всего не будет выделен. Решением данной проблемы может быть поиск объектов по аналитической зависимости, описывающей их форму.
Поиск по аналитическому описанию формы
Распространена практика поиска объектов по форме, имеющей аналитическое описание. Например, эллипс (или его частный случай – окружность) могут быть описаны несложной формулой из курса аналитической геометрии.
x 2 a 2 + y 2 b 2 = R 2 (2) {\displaystyle {\frac {x^{2}}{a^{2}}}+{\frac {y^{2}}{b^{2}}}=R^{2}\quad \quad {\color {Maroon}(2)}\,\!}По аналогии с методом поиска по шаблону для большинства точек изображения рассматривается их характеристика – в нее включаются значения яркостей точек, положение которых удовлетворяет аналитической зависимости.

Рис. 3. Вписывание эллипса в совокупность точек
В остальном этот метод аналогичен методу поиска по шаблону. Однако, ситуация когда объект искомой формы расположен в кадре нужным образом достаточно редка. Чаще всего отдельные элементы заслоняются или просто не видны, объект повернут и вообще мало похож на свою форму по аналитической зависимости или шаблону. В такой распространенной ситуации можно пытаться выделять отдельные фрагменты формы, например прямые линии.
Классификация по положению
Одним из наиболее наполненных эвристикой направлений в теории распознавания образов являются методы поиска по положению. В частности, при поиске лиц или других фрагментов тел в области кадра принимается допущение, что искомые области представляют собой продолговатые, чаще всего вытянутые в вертикальном направлении совокупности пикселей близких по яркости. Таким же образом используется множество других допущений относительно взаимного местоположения объектов – если на некий объект были нанесены легко отыскиваемые метки, или некие детали, изначально содержимые объектом, значительно проще классифицировать, чем весь объект в целом, то, обнаружив эти метки или детали, можно классифицировать содержащий их объект. То есть, если существует устойчивый метод выделения в кадре, например, глаз человека или носа, то можно по этим деталям сделать предположение, где находится все остальное. Исключения составляют атипичные случаи, когда объект в кадре обладает нетривиальным сочетанием этих деталей в неподходящих для распознавания положениях.
Классификация по цвету
Многие объекты можно классифицировать в зависимости от их цвета: они либо постоянно имеют определенную окраску, либо в некоторые моменты их окраска может быть регламентирована достаточно четко. Более того, в связи с тем, что существует множество базисов представления цветовых компонент (RGB, YUV, YCrCb, HSV и т.д.), нередки случаи, когда в том или ином базисе данный объект можно классифицировать практически безошибочно. Однако информация о том, какой базис использовать и как лучше организовать поиск объекта, имея в распоряжении изображение в данном базисе, зачастую может быть получена исключительно экспериментальным путем.
Базовые положения теории распознавания образов
Распознавание образов (объектов, сигналов, ситуаций, явлений или процессов) - задача идентификации объекта или определения каких-либо его свойств по его изображению (оптическое распознавание) или аудиозаписи (акустическое распознавание) и другим характеристикам.
Одним из базовых является не имеющее конкретной формулировки понятие множества. В компьютере множество представляется набором неповторяющихся однотипных элементов. Слово «неповторяющихся» означает, что какой-то элемент в множестве либо есть, либо его там нет. Универсальное множество включает все возможные для решаемой задачи элементы, пустое не содержит ни одного.
Образ - классификационная группировка в системе классификации, объединяющая (выделяющая) определенную группу объектов по некоторому признаку. Образы обладают характерным свойством, проявляющимся в том, что ознакомление с конечным числом явлений из одного и того же множества дает возможность узнавать сколь угодно большое число его представителей. Образы обладают характерными объективными свойствами в том смысле, что разные люди, обучающиеся на различном материале наблюдений, большей частью одинаково и независимо друг от друга классифицируют одни и те же объекты. В классической постановке задачи распознавания универсальное множество разбивается на части-образы. Каждое отображение какого-либо объекта на воспринимающие органы распознающей системы, независимо от его положения относительно этих органов, принято называть изображением объекта, а множества таких изображений, объединенные какими-либо общими свойствами, представляют собой образы.
Методика отнесения элемента к какому-либо образу называется решающим правилом. Еще одно важное понятие - метрика, способ определения расстояния между элементами универсального множества. Чем меньше это расстояние, тем более похожими являются объекты (символы, звуки и др.) - то, что мы распознаем. Обычно элементы задаются в виде набора чисел, а метрика - в виде функции. От выбора представления образов и реализации метрики зависит эффективность программы, один алгоритм распознавания с разными метриками будет ошибаться с разной частотой.
Обучением обычно называют процесс выработки в некоторой системе той или иной реакции на группы внешних идентичных сигналов путем многократного воздействия на систему внешней корректировки. Такую внешнюю корректировку в обучении принято называть «поощрениями» и «наказаниями». Механизм генерации этой корректировки практически полностью определяет алгоритм обучения. Самообучение отличается от обучения тем, что здесь дополнительная информация о верности реакции системе не сообщается.
Адаптация - это процесс изменения параметров и структуры системы, а возможно - и управляющих воздействий, на основе текущей информации с целью достижения определенного состояния системы при начальной неопределенности и изменяющихся условиях работы.
Обучение - это процесс, в результате которого система постепенно приобретает способность отвечать нужными реакциями на определенные совокупности внешних воздействий, а адаптация - это подстройка параметров и структуры системы с целью достижения требуемого качества управления в условиях непрерывных изменений внешних условий.
Примеры задач распознавания образов:
- pаспознавание букв;
- pаспознавание штрих-кодов;
- pаспознавание автомобильных номеров;
- pаспознавание лиц и других биометрических данных;
- pаспознавание изображений;
- pаспознавание речи.
Методы распознавания образов
В целом, можно выделить следующие методы распознавания образов:
- Метод перебора. В этом случае производится сравнение с базой данных, где для каждого вида объектов представлены всевозможные модификации отображения. Например, для оптического распознавания образов можно применить метод перебора вида объекта под различными углами, масштабами, смещениями, деформациями и т. д. Для букв нужно перебирать шрифт, свойства шрифта и т. д. В случае распознавания звуковых образов, соответственно, происходит сравнение с некоторыми известными шаблонами (например, слово, произнесенное несколькими людьми).
- Второй подход - производится более глубокий анализ характеристик образа. В случае оптического распознавания это может быть определение различных геометрических характеристик. Звуковой образец в этом случае подвергается частотному, амплитудному анализу и т. д.
- Следующий метод - использование искусственных нейронных сетей (ИНС). Этот метод требует либо большого количества примеров задачи распознавания при обучении, либо специальной структуры нейронной сети, учитывающей специфику данной задачи. Тем не менее, его отличает более высокая эффективность и производительность. .
- Экспертный метод, основанный на непрерывном обучении экспертной системы в процессе эксплатации.
Персептрон как метод распознавания образов
Ф. Розенблатт, вводя понятие о модели мозга, задача которой состоит в том, чтобы показать, как в некоторой физической системе, структура и функциональные свойства которой известны, могут возникать психологические явления - описал простейшие эксперименты по различению. Данные эксперименты целиком относятся к методам распознавания образов, но отличаются тем, что алгоритм решения не детерминированный. Простейший эксперимент, на основе которого можно получить психологически значимую информацию о некоторой системе, сводится к тому, что модели предъявляются два различных стимула и требуется, чтобы она реагировала на них различным образом. Целью такого эксперимента может быть исследование возможности их спонтанного различения системой при отсутствии вмешательства со стороны экспериментатора, или, наоборот, изучение принудительного различения, при котором экспериментатор стремится обучить систему проводить требуемую классификацию. В опыте с обучением персептрону обычно предъявляется некоторая последовательность образов, в которую входят представители каждого из классов, подлежащих различению. В соответствии с некоторым правилом модификации памяти правильный выбор реакции подкрепляется. Затем персептрону предъявляется контрольный стимул и определяется вероятность получения правильной реакции для стимулов данного класса. В зависимости от того, совпадает или не совпадает выбранный контрольный стимул с одним из образов, которые использовались в обучающей последовательности, получают различные результаты: 1. Если контрольный стимул не совпадает ни с одним из обучающих стимулов, то эксперимент связан не только с чистым различением, но включает в себя и элементы обобщения. 2. Если контрольный стимул возбуждает некоторый набор сенсорных элементов, совершенно отличных от тех элементов, которые активизировались при воздействии ранее предъявленных стимулов того же класса, то эксперимент является исследованием чистого обобщения. Персептроны не обладают способностью к чистому обобщению, но они вполне удовлетворительно функционируют в экспериментах по различению, особенно если контрольный стимул достаточно близко совпадает с одним из образов, относительно которых персептрон уже накопил определенный опыт.
Общая характеристика задач распознавания образов и их типы
Общая структура системы распознавания и этапы в процессе ее разработки показаны на рис. 4.

Рис. 4. Пример структуры системы распознавания
Задачи распознавания - это информационные задачи, состоящие из двух этапов:
- преобразование исходных данных к виду, удобному для распознавания;
- собственно распознавание (указание принадлежности объекта определенному классу).
В этих задачах можно вводить понятие аналогии или подобия объектов и формулировать правила, на основании которых объект зачисляется в один и тот же класс или в разные классы. В этих задачах можно оперировать набором прецедентов-примеров, классификация которых известна и которые в виде формализованных описаний могут быть предъявлены алгоритму распознавания для настройки на задачу в процессе обучения. Для этих задач трудно строить формальные теории и применять классические математические методы (часто недоступна информация для точной математической модели или выигрыш от использования модели и математических методов несоизмерим с затратами).
Выделяют следующие типы задач распознавания:
- задача распознавания - отнесение предъявленного объекта по его описанию к одному из заданных классов (обучение с учителем);
- задача автоматической классификации - разбиение множества объектов, ситуаций, явлений по их описаниям на систему непересекающихся классов (таксономия, кластерный анализ, самообучение);
- задача выбора информативного набора признаков при распознавании;
- задача приведения исходных данных к виду, удобному для распознавания;
- динамическое распознавание и динамическая классификация - задачи 1 и 2 для динамических объектов;
- задача прогнозирования - предыдущий тип, в котором решение должно относиться к некоторому моменту в будущем.
Распознавание образов, научное направление, связанное с разработкой принципов и построением систем, предназначенных для определения принадлежности данного объекта к одному из заранее выделенных классов объектов. Под объектами в распознавания образов понимают различные предметы, явления, процессы, ситуации, сигналы. Каждый объект описывается совокупностью основных характеристик (признаков, свойств) X = (x 1 , … , x i , … , x n) {\displaystyle X=(x_{1},\dots ,x_{i},\dots ,x_{n})} , где i {\displaystyle i} -я координата вектора X {\displaystyle X} определяет значения i {\displaystyle i} -й характеристики, и дополнительной характеристикой S {\displaystyle S} , которая указывает на принадлежность объекта к некоторому классу (образу). Набор заранее расклассифицированных объектов, т. е. таких, у которых известны характеристики X {\displaystyle X} и S {\displaystyle S} , используется для обнаружения закономерных связей между значениями этих характеристик, и поэтому называются обучающей выборкой. Те объекты, у которых характеристика S {\displaystyle S} неизвестна, образуют контрольную выборку. Отдельные объекты обучающей и контрольной выборок называются реализациями. Одна из основных задач Распознавания образов - выбор правила (решающей функции) D {\displaystyle D} , в соответствии с которым по значению контрольной реализации X {\displaystyle X} устанавливается её принадлежность к одному из образов, т. е. указываются «наиболее правдоподобные» значения характеристики S {\displaystyle S} для данного X {\displaystyle X} .
Успех в решении задачи Распознавания образов зависит в значительной мере от того, насколько удачно выбраны признаки X {\displaystyle X} . Исходный набор характеристик часто бывает очень большим. В то же время приемлемое правило должно быть основано на использовании небольшого числа признаков, наиболее важных для отличия одного образа от другого. Так, в задачах медицинской диагностики важно определить, какие симптомы и их сочетания (синдромы) следует использовать при постановке диагноза данного заболевания. Поэтому проблема выбора информативных признаков - важная составная часть проблемы распознавания образов
Проблема распознавания образов тесно связана с задачей предварительной классификации, или таксономией.
В основной задаче распознавания образов построения решающих функций D {\displaystyle D} используются закономерные связи между характеристиками X {\displaystyle X} и S {\displaystyle S} , обнаруживаемые на обучающей выборке, и некоторые дополнительные априорные предположения, например, следующие гипотезы: характеристики X {\displaystyle X} для реализаций образов представляют собой случайные выборки из генеральных совокупностей с нормальным распределением; реализации одного образа расположены «компактно» (в некотором смысле); признаки в наборе X {\displaystyle X} независимы и т.д.
В области Распознавания образов существенно используются идеи и результаты многих др. научных направлений - математики, кибернетики, психологии и т.д.
В 60-х гг. 20 в. в связи с развитием, электронной техники, в частности ЭВМ, широкое применение получили автоматические системы распознавания. Под системами распознавания обычно понимают комплексы средств, предназначенных для решения описанных выше, задач. Методы Распознавания образов используются в процессе машинной диагностики различных заболеваний, для прогнозирования полезных ископаемых в геологии, для анализа экономических и социальных процессов, в психологии, криминалистике, лингвистике, океанологии, химии, ядерной и космической физике, в автоматизированных системах управления и т.д. Их применение оправдано практически всюду, где приходится иметь дело с классификацией экспериментальных данных.
Одним из способов решения задачи распознавания образов является использование спектральных методов.
С задачей распознавания образов живые системы, в том числе и человек, сталкиваются постоянно с момента своего появления. В частности, информация, поступающая с органов чувств, обрабатывается мозгом, который в свою очередь сортирует информацию, обеспечивает принятие решения, а далее с помощью электрохимических импульсов передает необходимый сигнал далее, например, органам движения, которые реализуют необходимые действия. Затем происходит изменение окружающей обстановки, и вышеуказанные явления происходят заново. И если разобраться, то каждый этап сопровождается распознаванием.
С развитием вычислительной техники стало возможным решить ряд задач, возникающих в процессе жизнедеятельности, облегчить, ускорить, повысить качество результата. К примеру, работа различных систем жизнеобеспечения, взаимодействие человека с компьютером, появление роботизированных систем и др. Тем не менее, отметим, что обеспечить удовлетворительный результат в некоторых задачах (распознавание быстродвижущихся подобных объектов, рукописного текста) в настоящее время не удается.
Цель работы: изучить историю систем распознавания образов.
Указать качественные изменения произошедшие в области распознавания образов как теоретические, так и технические, с указанием причин;
Обсудить методы и принципы, применяемые в вычислительной технике;
Привести примеры перспектив, которые ожидаются в ближайшем будущем.
1. Что такое распознавание образов?
Первые исследования с вычислительной техникой в основном следовали классической схеме математического моделирования - математическая модель, алгоритм и расчет. Таковыми были задачи моделирования процессов происходящих при взрывах атомных бомб, расчета баллистических траекторий, экономических и прочих приложений. Однако помимо классических идей этого ряда возникали и методы основанные на совершенно иной природе, и как показывала практика решения некоторых задач, они зачастую давали лучший результат нежели решения, основанные на переусложненных математических моделях. Их идея заключалась в отказе от стремления создать исчерпывающую математическую модель изучаемого объекта (причем зачастую адекватные модели было практически невозможно построить), а вместо этого удовлетвориться ответом лишь на конкретные интересующие нас вопросы, причем эти ответы искать из общих для широкого класса задач соображений. К исследованиям такого рода относились распознавание зрительных образов, прогнозирование урожайности, уровня рек, задача различения нефтеносных и водоносных пластов по косвенным геофизическим данным и т. д. Конкретный ответ в этих задачах требовался в довольно простой форме, как например, принадлежность объекта одному из заранее фиксированных классов. А исходные данные этих задач, как правило, задавались в виде обрывочных сведений об изучаемых объектах, например в виде набора заранее расклассифицированных объектов. С математической точки зрения это означает, что распознавание образов (а так и был назван в нашей стране этот класс задач) представляет собой далеко идущее обобщение идеи экстраполяции функции.
Важность такой постановки для технических наук не вызывает никаких сомнений и уже это само по себе оправдывает многочисленные исследования в этой области. Однако задача распознавания образов имеет и более широкий аспект для естествознания (впрочем, было бы странно если нечто столь важное для искусственных кибернетических систем не u1080 имело бы значения для естественных). В контекст данной науки органично вошли и поставленные еще древними философами вопросы о природе нашего познания, нашей способности распознавать образы, закономерности, ситуации окружающего мира. В действительности, можно практически не сомневаться в том, что механизмы распознавания простейших образов, типа образов приближающегося опасного хищника или еды, сформировались значительно ранее, чем возник элементарный язык и формально-логический аппарат. И не вызывает никаких сомнений, что такие механизмы достаточно развиты и у высших животных, которым так же в жизнедеятельности крайне необходима способность различения достаточно сложной системы знаков природы. Таким образом, в природе мы видим, что феномен мышления и сознания явно базируется на способностях к распознаванию образов и дальнейший прогресс науки об интеллекте непосредственно связан с глубиной понимания фундаментальных законов распознавания. Понимая тот факт, что вышеперечисленные вопросы выходят далеко за рамки стандартного определения распознавания образов (в англоязычной литературе более распространен термин supervised learning), необходимо так же понимать, что они имеют глубокие связи с этим относительно узким(но все еще далеко неисчерпанным) направлением .
Уже сейчас распознавание образов плотно вошло в повседневную жизнь и является одним из самых насущных знаний современного инженера. В медицине распознавание образов помогает врачам ставить более точные диагнозы, на заводах оно используется для прогноза брака в партиях товаров. Системы биометрической идентификации личности в качестве своего алгоритмического ядра так же основаны на результатах этой дисциплины. Дальнейшее развитие искусственного интеллекта, в частности проектирование компьютеров пятого поколения, способных к более непосредственному общению с человеком на естественных для людей языках и посредством речи, немыслимы без распознавания. Здесь рукой подать и до робототехники, искусственных систем управления, содержащих в качестве жизненно важных подсистем системы распознавания.
Именно поэтому к развитию распознавания образов с самого начала было приковано немало внимания со стороны специалистов самого различного профиля - кибернетиков, нейрофизиологов, психологов, математиков, экономистов и т.д. Во многом именно по этой причине современное распознавание образов само питается идеями этих дисциплин. Не претендуя на полноту (а на нее в небольшом эссе претендовать невозможно) опишем историю распознавания образов, ключевые идеи .
Определения
Прежде, чем приступить к основным методам распознавания образов, приведем несколько необходимых определений.
Распознавание образов (объектов, сигналов, ситуаций, явлений или процессов) - задача идентификации объекта или определения каких-либо его свойств по его изображению (оптическое распознавание) или аудиозаписи (акустическое распознавание) и другим характеристикам.
Одним из базовых является не имеющее конкретной формулировки понятие множества. В компьютере множество представляется набором неповторяющихся однотипных элементов. Слово "неповторяющихся" означает, что какой-то элемент в множестве либо есть, либо его там нет. Универсальное множество включает все возможные для решаемой задачи элементы, пустое не содержит ни одного.
Образ - классификационная группировка в системе классификации, объединяющая (выделяющая) определенную группу объектов по некоторому признаку. Образы обладают характерным свойством, проявляющимся в том, что ознакомление с конечным числом явлений из одного и того же множества дает возможность узнавать сколь угодно большое число его представителей. Образы обладают характерными объективными свойствами в том смысле, что разные люди, обучающиеся на различном материале наблюдений, большей частью одинаково и независимо друг от друга классифицируют одни и те же объекты. В классической постановке задачи распознавания универсальное множество разбивается на части-образы. Каждое отображение какого-либо объекта на воспринимающие органы распознающей системы, независимо от его положения относительно этих органов, принято называть изображением объекта, а множества таких изображений, объединенные какими-либо общими свойствами, представляют собой образы.
Методика отнесения элемента к какому-либо образу называется решающим правилом. Еще одно важное понятие - метрика, способ определения расстояния между элементами универсального множества. Чем меньше это расстояние, тем более похожими являются объекты (символы, звуки и др.) - то, что мы распознаем. Обычно элементы задаются в виде набора чисел, а метрика - в виде функции. От выбора представления образов и реализации метрики зависит эффективность программы, один алгоритм распознавания с разными метриками будет ошибаться с разной частотой.
Обучением обычно называют процесс выработки в некоторой системе той или иной реакции на группы внешних идентичных сигналов путем многократного воздействия на систему внешней корректировки. Такую внешнюю корректировку в обучении принято называть "поощрениями" и "наказаниями". Механизм генерации этой корректировки практически полностью определяет алгоритм обучения. Самообучение отличается от обучения тем, что здесь дополнительная информация о верности реакции системе не сообщается.
Адаптация - это процесс изменения параметров и структуры системы, а возможно - и управляющих воздействий, на основе текущей информации с целью достижения определенного состояния системы при начальной неопределенности и изменяющихся условиях работы.
Обучение - это процесс, в результате которого система постепенно приобретает способность отвечать нужными реакциями на определенные совокупности внешних воздействий, а адаптация - это подстройка параметров и структуры системы с целью достижения требуемого качества управления в условиях непрерывных изменений внешних условий.
Примеры задач распознавания образов: - Распознавание букв;